Build in Public #13 : Quand le CV ment et les vues ne comptent pas
Les données de surface mentent. Sur ResumeRank, le CV ne suffit plus : j'ai construit un agent qui va chercher LinkedIn. Sur Sam Tennis, les vues ne font pas la rétention : j'ai intégré 73 000 joueurs FFT et un coach proactif. Retour sur un mois de croisement de données.
TL;DR :
- Le constat commun : Sur mes deux projets, les données de surface (le CV sur ResumeRank, les vues/téléchargements sur Sam Tennis) ne suffisent pas. Il faut aller les croiser avec des sources externes fiables.
- ResumeRank : Un retour prospect m'a montré que le scoring basé uniquement sur le CV créait un écart trop important en entretien. J'ai construit un agent de recherche LinkedIn automatisé pour croiser les données. Côté business : premier client étranger en self-service, nouveau client Entreprise, et un test institutionnel à venir.
- Sam Tennis : La V2 est soumise à l'App Store ce matin. J'ai intégré les données de la Fédération Française de Tennis (73 000+ joueurs, 680 000 matchs), construit un coach proactif qui détecte les matchs à venir dans les conversations, et reconfiguré tout le tracking PostHog. Premier virement Apple reçu : 8€.
- La leçon : Ne pas compter sur l'utilisateur pour te donner l'information. Va la chercher toi-même, là où elle est fiable.
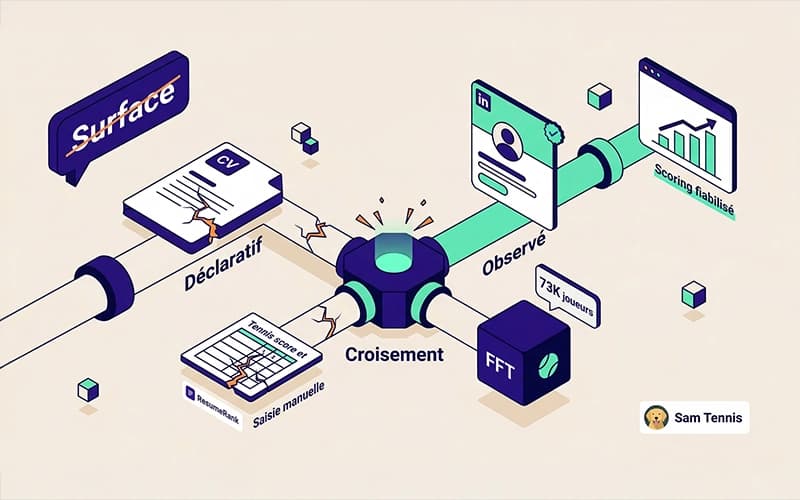
Données déclaratives vs données observées : les données déclaratives sont ce que l'utilisateur te dit (CV, saisie manuelle). Les données observées sont ce que des sources externes confirment (profil LinkedIn, résultats FFT). Le croisement des deux est ce qui fiabilise un produit.
Ma Stack pour ce mois
Voir tous les outilsPostHog pour le tracking V2 de Sam Tennis. Cursor pour construire l'agent LinkedIn et restructurer l'application.
Product analytics et session replay
L'IDE nouvelle génération avec IA intégrée
Certains liens sont des liens affiliés. Je ne recommande que des outils que j'utilise réellement.
Salut 👋
Si tu as lu le chapitre précédent, tu sais que j'ai ouvert le capot de Sam Tennis via PostHog. Le verdict était brutal : rétention quasi-nulle, 85% de la base utilisateur non exploitable, tunnel cassé.
La bonne nouvelle, c'est que j'ai tout reconstruit depuis. La mauvaise nouvelle, c'est que le problème de fond était le même sur mes deux projets : je me fiais à des données de surface.
Sur ResumeRank, je faisais confiance au CV. Sur Sam Tennis, je faisais confiance aux vues et aux téléchargements. Dans les deux cas, ces données donnaient une image déformée de la réalité. Il m'a fallu un feedback client sur ResumeRank et un audit PostHog sur Sam Tennis pour m'en rendre compte.
Ce mois-ci, j'ai croisé les sources. Voici ce que ça a changé.
1. ResumeRank : quand le CV ne suffit plus
Le feedback qui a tout remis en question
J'ai eu une prospect qui a testé l'outil pendant 14 jours. Son retour : l'outil fonctionne, les analyses sont pertinentes, il y avait 2-3 bugs (corrigés depuis). Mais le facteur bloquant pour elle, c'était l'écart entre ce que les candidats annoncent sur leur CV et ce qu'ils montrent en entretien.
Le problème est structurel. Les candidats utilisent ChatGPT pour réécrire leurs CV avec les bons mots-clés. Ils optimisent leur document pour passer les filtres IA. Résultat : le scoring monte, mais la qualité réelle du candidat ne suit pas forcément. L'outil donne un bon classement, le recruteur convoque, et il y a de la déception en entretien.
Je ne peux pas contrôler ce que les candidats écrivent dans leur CV. Par contre, je peux aller chercher une deuxième source de données pour croiser l'information.
L'agent LinkedIn : la deuxième source
LinkedIn est cette deuxième source. Sur un profil public, on peut difficilement s'inventer un poste dans une entreprise, on ne peut pas tricher sur la durée de ses expériences (les dates sont affichées), et la validation sociale (recommandations, compétences confirmées) donne un signal supplémentaire.
Avant, ResumeRank ne récupérait le profil LinkedIn que si le candidat avait mis son URL dans le CV. En pratique, beaucoup ne le font pas. Ça me privait d'une source de données sur une grande partie des candidats analysés.
J'ai construit un agent de recherche automatisé avec Cursor. Pour chaque candidat analysé, l'agent va chercher le profil LinkedIn correspondant, même si le candidat n'a pas indiqué son URL. Le pipeline fonctionne en 4 étapes :
- Recherche web du profil LinkedIn à partir du nom, du poste et de l'entreprise
- Validation par LLM pour s'assurer que c'est la bonne personne (0% de faux positifs visé)
- Extraction des données du profil public
- Croisement avec le CV pour fiabiliser le scoring

L'objectif est d'augmenter le taux de matching entre CV et profil LinkedIn pour avoir plus de données à disposition et fiabiliser le scoring. C'est en production depuis ce week-end. Les premiers résultats sur les taux de matching donneront une bonne indication de la valeur ajoutée réelle.
Le business : premiers signaux de croissance organique
Côté clients, le mois a été intéressant. Mon premier client historique a résilié son abonnement. C'est le jeu. Mais en face :
- J'ai signé de nouveaux clients, dont un sur le plan Entreprise avec l'intégration WeRecruit (API).
- Un test est prévu avec une organisation institutionnelle française qui aura plusieurs utilisateurs. Si ça se confirme, ce sera un contrat significatif.
- Et surtout : j'ai eu mon premier client étranger qui s'est inscrit et a upgradé seul, sans que j'aie besoin d'intervenir. Zéro appel, zéro email. Le tunnel d'acquisition en self-service fonctionne.
De nouveaux utilisateurs arrivent tous les jours. Encore pas mal d'étudiants (qui utilisent l'analyse CV gratuite pour optimiser leur candidature), mais de plus en plus de profils RH. Affaire à suivre.
2. Sam Tennis : de coach passif à coach proactif
Le problème de la V1 : un coach qui attend
Le diagnostic PostHog du chapitre précédent était clair : les joueurs téléchargent l'app, l'ouvrent quelques fois, et arrêtent.
Mon hypothèse : le coach Sam se comportait comme un chatbot. Il attendait que le joueur vienne lui parler. Un vrai coach ne fait pas ça. Un vrai coach envoie un message la veille du match pour demander si le plan de jeu est prêt. Il relance le lendemain pour le débrief. Il se souvient de ta blessure au coude et te demande comment ça évolue.
C'est exactement ce que j'ai construit ce mois-ci. Et pour que Sam puisse être proactif, il lui fallait deux choses : des données fiables sur le joueur, et la capacité de détecter les événements importants.
L'intégration FFT : 73 000 joueurs, 680 000 matchs
J'ai récupéré les données de la Fédération Française de Tennis. Concrètement, j'ai accès à une base de plus de 73 000 joueurs et 680 000 matchs.
À l'onboarding, on demande au joueur son numéro de licence FFT (7 chiffres). Ce numéro me sert d'ID de matching : je retrouve le joueur dans la base FFT et je synchronise automatiquement son historique. Stats de performance, taux de victoire par saison, forme récente, adversaires rencontrés, classement officiel. Tout arrive sans que le joueur ait à saisir quoi que ce soit.
Dans la V1, l'utilisateur devait rentrer chaque match à la main. Dans l'audit PostHog, on voyait le résultat : 0 débrief enregistré, 3 adversaires saisis manuellement pour 57 joueurs. Personne ne le faisait. Maintenant, c'est automatique.
Le coach proactif : Sam qui vient vers toi
La deuxième brique, c'est le RAG conversationnel en temps réel. Sam analyse les conversations et détecte automatiquement les événements importants. Si un joueur dit dans le chat "j'ai un match dimanche", Sam enregistre l'information et planifie des notifications.
Concrètement :
- La veille au soir : Sam envoie un push pour demander comment se passe la préparation, ce que le joueur a mangé, s'il a un plan de jeu.
- Le jour du match : message de motivation et rappel tactique.
- Après le match : Sam relance pour le débrief. Comment ça s'est passé, quel était le ressenti, quel a été le plan de jeu, quels ajustements pour la prochaine fois.
L'idée est de reproduire ce qu'un vrai coach ferait sur WhatsApp. Un partenaire qui maintient la relation entre les sessions, pas un assistant passif qu'on ouvre quand on y pense. Si ça fonctionne, ça devrait améliorer significativement le taux de rétention identifié dans l'audit de la V1.

La V2 : soumise à Apple ce matin
J'ai soumis la V2 à l'App Store Connect ce mardi 31 mars. En plus de l'intégration FFT et du coach proactif, cette version inclut :
- Tous les events PostHog reconfigurés pour récupérer proprement les données utilisateurs (plus de 85% de base inexploitable)
- Une application restructurée et simplifiée grâce à la méthode BMAD
- Un modèle IA plus performant
- Un paywall mieux adapté
- Un onboarding plus court pour réduire la friction à l'entrée
J'attends la validation Apple. Historiquement, ça prend entre 24h et une semaine. Une fois validée, je relance la distribution : j'ai une dizaine de vidéos prêtes à poster.
3. La leçon : va chercher la donnée là où elle est
Le point commun entre les deux projets ce mois-ci, c'est que j'ai arrêté de compter sur l'utilisateur pour me donner l'information.
Sur ResumeRank, le candidat met ce qu'il veut dans son CV. Il peut exagérer, enjoliver, optimiser pour les mots-clés. La donnée fiable, elle est sur LinkedIn, où le profil est public et socialement validé.
Sur Sam Tennis, le joueur n'a pas envie de saisir manuellement ses matchs après chaque partie. La donnée fiable, elle est à la FFT, qui enregistre tous les résultats officiels.
Dans les deux cas, la solution a été la même : aller chercher la donnée à la source, automatiquement, sans demander d'effort à l'utilisateur.
Si ton produit repose sur des données déclaratives (ce que l'utilisateur te dit), tu as un problème de fiabilité. Dès que tu peux les croiser avec des données observées (ce que des sources externes confirment), ta valeur augmente.

Le CV est déclaratif. LinkedIn est observé. La saisie manuelle est déclarative. La FFT est observée. Le croisement des deux est ce qui fait la fiabilité.
4. Le point finances
Sam Tennis
J'ai mis en pause la distribution de Sam Tennis pendant la refonte. Le tunnel de rétention de la V1 était cassé, ça ne servait à rien de continuer à pousser des utilisateurs dans un produit qui ne les retient pas. Si tu veux comprendre pourquoi, l'audit PostHog explique tout.
Côté revenus, j'ai reçu mon premier virement d'Apple. Il faut savoir qu'Apple a un délai de 2 à 3 mois entre les premières inscriptions et le virement. Résultat : 8€. C'est ridicule, mais c'est un premier virement. Le mois prochain, ce sera environ 40€. Et si les gens restent abonnés, ça se cumule.
En chiffre d'affaires total depuis le lancement, Sam Tennis m'a rapporté une cinquantaine d'euros. Je vais reprendre la distribution une fois la V2 validée, avec une meilleure application, un meilleur paywall, et un meilleur onboarding. J'espère pouvoir comparer les métriques V2 avec celles de la V1 dans le prochain épisode.
ResumeRank
La dynamique est meilleure. Le premier churn est compensé par de nouveaux clients, dont le plan Entreprise. Le client étranger en self-service est un bon signal : le produit commence à se vendre sans moi. Le test institutionnel pourrait accélérer les choses si ça se concrétise. Je suis à 200€ de MRR sur ResumeRank, ce chiffre pourrait doubler en fonction du retour du test à venir.
Conclusion : les données de surface sont un piège
Ce mois-ci m'a appris que la première couche de données est souvent trompeuse. Le CV donne l'impression d'être complet, mais les candidats l'optimisent avec ChatGPT pour passer les filtres. Les 300 000 vues TikTok ont généré trop peu d'utilisateurs durables. Et les téléchargements sans rétention, c'est un château de sable.
La vraie valeur arrive quand tu croises tes sources. Quand tu confrontes le déclaratif à l'observé. Quand tu vas chercher la donnée là où elle est fiable au lieu de te contenter de ce que l'utilisateur veut bien te montrer.
Les 3 points clés à retenir
- • Données déclaratives vs observées : Le CV est déclaratif (le candidat écrit ce qu'il veut). LinkedIn est observé (le profil est public et socialement validé). Le croisement des deux fiabilise le scoring de ResumeRank.
- • Le coach proactif : Sam Tennis passe de chatbot passif à coach qui détecte les matchs dans la conversation et relance avant, pendant et après. L'objectif : casser la rétention quasi-nulle de la V1.
- • Le self-service fonctionne : Premier client étranger inscrit et upgradé sans aucune intervention de ma part. Le tunnel d'acquisition de ResumeRank tourne tout seul.
À très vite,
Guillaume 👋
🎯 Construis ta propre machine
Tu veux savoir quels outils utiliser pour ton projet Solo Builder ? Mon simulateur gratuit te recommande la stack adaptée à ton profil et tes objectifs.
Lancer le Simulateur Solo Builder
Questions fréquentes
Comment un agent IA peut-il trouver un profil LinkedIn sans URL ?
L'agent utilise les informations du CV (nom complet, poste actuel, entreprise) pour lancer une recherche web ciblée. Un LLM valide ensuite que le profil trouvé correspond bien au candidat en croisant plusieurs critères (nom, parcours, localisation). L'objectif est 0% de faux positifs : si le LLM n'est pas sûr, il ne retourne pas de matching.
Pourquoi LinkedIn est-il plus fiable que le CV pour le scoring ?
Sur un CV, le candidat contrôle 100% de l'information sans vérification externe. Sur LinkedIn, les postes sont visibles par les anciens collègues, les durées d'expérience sont affichées avec des dates précises, et les recommandations constituent une validation sociale. Le coût de mentir sur LinkedIn est beaucoup plus élevé que sur un CV.
Le coach proactif améliore-t-il vraiment la rétention ?
Je n'ai pas encore les données : la V2 vient d'être soumise à Apple. Mon hypothèse est que la rétention de la V1 était proche de zéro parce que Sam attendait que le joueur vienne. Un coach qui détecte les matchs et relance avec des notifications avant et après devrait maintenir l'engagement entre les sessions. Je partagerai les premières métriques dès que j'aurai assez de données.
Pour aller plus loin
- Build in Public #12 : L'audit PostHog - L'audit qui a révélé le problème de rétention
- Guide Complet PostHog 2026 - Le tracking, le MCP, les Feature Flags
- Build in Public #11 : La méthode BMAD - Comment j'ai structuré la V2 de Sam Tennis
- Build in Public #9 : L'intégration WeRecruit - Le Growth Hack B2B de ResumeRank
- Build in Public #8 : 150 000 vues pour 33€ - La stratégie contenu qui a généré les vues
- Guide Cursor 2026 - L'IDE avec lequel j'ai construit l'agent LinkedIn
- Voir tous mes outils recommandés
Tu veux suivre la suite de cette aventure Build in Public ?
Rejoindre 2000+ Solo Builders